Nonmem Data to PoPy Data File¶
The Nonmem data file has the same purpose as the PoPy data file. It represents the observations at different time points and the dosing regimens for each subject.
For simple data sets you may only need to substitute a few values to create a valid PoPy data file. If you have multiple dosing regimes and multiple measurements then the conversion may be more difficult.
Table 41 lists the the PoPy data fields for each Nonmem data field. Each subsection gives a one to one example conversion to PoPy format.
| Nonmem | PoPy | Comment |
|---|---|---|
| EVID | TYPE | Data row property field |
| ID | ID | Identity field |
| TIME | TIME | Time field |
| CMT | N/A | Compartment field |
| AMT | AMT | Dose Amount field |
| DV | Observation field | Observations |
| MDV | Observation flag field | Missing observations |
Both PoPy and Nonmem need to load a data file when estimating parameters. See $DATA for Nonmem’s method of specifying the input data file path and how to specify the input data file path in a PoPy Fit Script.
EVID¶
‘EVID’ is a required field in Nonmem. There is an equivalent required TYPE field in PoPy. The major difference is that Nonmem ‘EVID’ uses integers to define row properties, whereas PoPy uses human readable strings as shown in Table 42.
| Nonmem EVID | PoPy TYPE | Comment |
|---|---|---|
| 0 | obs | Observation Row |
| 1 | dose | Dosing Row |
| 2 | pred | Prediction Row |
| 3 | reset | Reset Row |
| 4 | reset+dose | Reset and Dose Row |
Note in PoPy the ‘dose’ TYPE entry can have a name suffix using PoPy’s ‘:’ notation. See specifying multiple dose types in PoPy for more details.
ID¶
‘ID’ is a required field in Nonmem and PoPy. The ‘ID’ column defines the individual for each data row. It is usually not necessary to convert the ‘ID’ column of the data set.
However, note that in PoPy the same identifier in the ‘ID’ field is always treated as the same individual. In Nonmem only identical identifiers that are in consecutive rows are treated as one individual.
For example in Table 43.
| ID | Nonmem | PoPy |
|---|---|---|
| Bill | New id | New id |
| Bill | Bill again | Bill again |
| Sandra | New id | New id |
| Bill | New id | Bill again |
| Sandra | New id | Sandra again |
Nonmem thinks there are 4 subjects, whilst PoPy thinks there are 2.
TIME¶
‘TIME’ is a required field in Nonmem and PoPy. The ‘TIME’ column defines the time stamp for each row. It is usually not necessary to convert the ‘TIME’ column of the data set.
In both Nonmem and PoPy the time field is required to be monotonically increasing, unless a EVID = 3 or 4 row is reached. In PoPy time is reset when a TYPE = ‘reset’ or ‘reset+dose’ row is reached.
One complication that can arise is if the Nonmem data is split over date and time, for example see Table 44.
| Nonmem date | Nonmem time | PoPy time |
|---|---|---|
| 2016-02-12 | 10:30 | 0.0 |
| 2016-02-13 | 19:01 | 32.5167 |
| 2016-02-13 | 19:02 | 32.5333 |
| 2016-02-13 | 23:39 | 37.15 |
| 2016-02-13 | 23:42 | 37.2 |
| 2016-02-14 | 10:06 | 47.6 |
Here the data for each individual needs to be converted to the time after the first record (or time since last reset) for use in PoPy.
CMT¶
The ‘CMT’ field in Nonmem is used to specify the index of the compartment where doses will be administered. i.e. rows with EVID=1 or EVID=4, with CMT=x will result in an bolus or infusion dose being administered in the compartment numbered ‘x’ in the $DES section of the Nonmem control file.
PoPy deliberately does not specify the dose compartment in the data file. Instead the dose compartment is specified in the DERIVATIVES section by the location of the Dosing Functions.
If the data only contains one type of dose, e.g. one drug which is always a bolus or always an infusion, then you can just ignore the ‘CMT’ field when converting to PoPy format.
If the data contains multiple types of dose however then PoPy needs a way of distinguishing between the two types (Nonmem uses a different CMT integer typically). In PoPy you need to give the dose a name, using the ‘:’ notation. An example data conversion with two types of dose is shown in Table 45.
| Nonmem evid | Nonmem cmt | PoPy type | Comment |
|---|---|---|---|
| 1 | 1 | dose:first_drug | drug one in first compartment |
| 1 | 1 | dose:first_drug | drug one in first compartment |
| 1 | 3 | dose:second_drug | drug two in third compartment |
| 1 | 1 | dose:first_drug | drug one in first compartment |
Note that the PoPy format above, leaves the destination compartment of each drug to be determined in the script file (the DERIVATIVES section), because the depot compartment for each drug is primarily a modelling decision, which might be changed in later analyses.
AMT¶
The Nonmem AMT field specifies the amount of each dose. The same field can be used in PoPy, so usually the AMT field needs no conversion.
Nonmem only allows a single AMT field to be used. If you have multiple doses, e.g. for two different drugs, then Nonmem forces you to put all dose amount values in a single column in your data file, even if the amounts are in different units.
In your PoPy data file you might want to take the opportunity to use separate columns, e.g. ‘AMT_DRUG1’, ‘AMT_DRUG2’ as a way of making your data file and script file clearer.
DV¶
The Nonmem DV field specifies the observed measurements in a data file. For example plasma drug concentration for a PK study or biomarker data in a PD trial. The same field can be used in PoPy, so often the DV field requires no conversion.
However Nonmem only allows a single DV field to be used. If you have multiple types of measurement in a study then Nonmem forces you to place all measurement values in a single column, even if the values have different units.
In your PoPy data file you might like to split the DV data into separate columns, e.g. ‘CONC’, and ‘MARKER’. This will make your data file and script file easier to read.
An example data conversion with two types of measurement is shown in Table 46.
| Nonmem DV | CONC | CONC_FLAG | MARKER | MARKER_FLAG | Comment |
|---|---|---|---|---|---|
| 5.3 | 5.3 | 1 | 0 | 0 | conc obs |
| 3 | 0 | 0 | 3 | 1 | marker obs |
| 5 | 0 | 0 | 5 | 1 | marker obs |
| 12.1 | 12.1 | 1 | 0 | 0 | conc obs |
Note in Table 46 it is necessary to use the ‘_FLAG’ field convention. The ‘_FLAG’ field is similar to the Nonmem MDV field, but you can have multiple ‘_FLAG’ fields. In a flag field ‘1’ means use this observation, ‘0’ means ignore. The flag field means you don’t have to use ‘if statements’ in the PREDICTIONS section.
MDV¶
The Nonmem MDV (missing data value) column is used to ignore some observations. It is similar in function to the PoPy flag field syntax described in DV.
However the MDV indicator contains a double negative, an observation is valid in Nonmem if MDV=0, i.e. it is not missing. The PoPy flag field is just yes/no, i.e. an observation X is valid if X_FLAG =1.
An example DV/MDV conversion is shown in Table 47.
| Nonmem DV | Nonmem MDV | CONC | CONC_FLAG | Comment |
|---|---|---|---|---|
| 5.3 | 0 | 5.3 | 1 | valid obs |
| na | 1 | 0.0 | 0 | invalid obs |
| 0.0 | 1 | 0.0 | 0 | invalid obs |
| 2.9 | 0 | 2.9 | 1 | valid obs |
Here:-
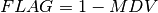
Also, in Nonmem you are only allowed to have one MDV field, which makes it less useful when you have multiple types of measurement.