Fitting a Two Compartment PopPK Model¶
The Fitting a Simple PopPK Model using PoPy shows fitting a one compartment PK model, to pre-existing data. In this example, we again utilise a pre-existing data set. We will demonstrate how to fit a two compartment model with absorption and bolus dosing, see Fig. 40:-

Fig. 40 Two compartment model with depot dosing for Fit Script. Here c[AMT] is the size of the bolus dose specified in the data file. m[KA], m[CL], m[Q], m[V1], m[V2] are all MODEL_PARAMS to be estimated for each individual.
This model is called a two compartment model, because the Depot is not included, as is conventional in PK models.
This PoPy model is also created by default when Creating an example Fit Script, using popy_create.
Note
See the First order absorption model with peripheral compartment obtained by the PoPy developers for this example, including input script and input data file.
Run the Fit Script¶
This fitting example uses these two files:-
c:\PoPy\examples\builtin_fit_example.pyml
builitin_fit_example_data.csv
Open a PoPy Command Prompt to setup the PoPy environment in this folder:-
c:\PoPy\examples\
With the PoPy environment enabled, do:-
$ popy_edit builtin_fit_example.pyml
To view the script in an editor and then run the Fit Script using popy_run from the command line:-
$ popy_run builtin_fit_example.pyml
When the fit script has completed, you can view the output of the fit using popy_view, by typing the following command:-
$ popy_view builtin_fit_example.pyml.html
Note the extra ‘.html’ extension in the above command. This command opens a local .html file in your web browser to summarise the result of the fitting.
You can compare your local html output with the pre-computed documentation output, see First order absorption model with peripheral compartment. You should expect some minor numerical differences when comparing results with the documentation.
Summary of Fit Results¶
The results of running the fitting script are PoPy’s best estimate for the presumed unknown fixed effects variables:-
f[KA] = 0.1846
f[CL] = 1.6740
f[V1] = 47.5042
f[Q] = 1.7764
f[V2] = 109.6770
f[KA_isv,CL_isv,V1_isv,Q_isv,V2_isv] = [
[ 0.0965, 0.0418, -0.0532, -0.0200, -0.0172 ],
[ 0.0418, 0.1443, 0.0079, -0.1026, -0.1679 ],
[ -0.0532, 0.0079, 0.0369, -0.0123, -0.0301 ],
[ -0.0200, -0.1026, -0.0123, 0.1982, 0.2090 ],
[ -0.0172, -0.1679, -0.0301, 0.2090, 0.2667 ],
]
f[PNOISE] = 0.1337
The aim of a Fit Script is to optimise the fixed effects and random effects maximizing the likelihood of observing the input data given the model structure defined in ‘builtin_fit_example.pyml’. The input data in this case, is the c[DV_CENTRAL] column in ‘builtin_fit_example_data.csv’, which contains 50 individuals each with 5 observations at random time points following a bolus dose event.
You can visually compare the fitted f[X] outputs with the input data, see Table 23.

|

|

|
In the graphs above the blue dots represent the original data points. The solid blue line represents the model individual predictions given the final f[X] parameters and fitted r[X] values for each individual. The dashed blue lines represent the model population predictions given final f[X] parameters and r[X] values set to zero.
Note in this model a bolus dose is received by all individuals at time 2.0. Then the amount of drug in the Central compartment follows a complex PK curve as it is first absorbed form the Depot compartment and then eliminated over time, whilst also interacting with the Peripheral compartment.
The graphs show that PoPy has adjusted the f[X] and r[X] parameters, so that the PK curves more closely match the input data and therefore maximise the likelihood of the data being generated from this model.
The data file included in this example is synthesized from the PK model of the same form described in ‘builtin_fit_example.pyml’ (see Generate a Two Compartment PopPK Data Set). So in this case, the model structure is known to be correct, so we should expect a good model fit.
Syntax of Fit Script¶
The mixed effect population structure is defined in the EFFECTS section as follows:-
EFFECTS:
POP: |
f[KA] ~ P1.0
f[CL] ~ P1.0
f[V1] ~ P20
f[Q] ~ P0.5
f[V2] ~ P100
f[KA_isv,CL_isv,V1_isv,Q_isv,V2_isv] ~ spd_matrix() [
[0.05],
[0.01, 0.05],
[0.01, 0.01, 0.05],
[0.01, 0.01, 0.01, 0.05],
[0.01, 0.01, 0.01, 0.01, 0.05],
]
f[PNOISE] ~ P0.1
ID: |
r[KA, CL, V1, Q, V2] ~ mnorm([0,0,0,0,0], f[KA_isv,CL_isv,V1_isv,Q_isv,V2_isv])
There are 5 mean fixed effect parameters i.e. f[KA], f[CL], f[V1], f[Q], f[V2], a 5x5 covariance matrix f[KA_isv, CL_isv, V1_isv, Q_isv, V2_isv], a proportional noise variable f[PNOISE] and a 5 element vector r[KA, CL, V1, Q, V2] of random effects defined for each individual. There are 50 individuals in the data set, therefore this model is attempting to estimate 6 main f[X] parameters, 15 variance f[X] parameters (the covariance matrix is symmetric) and 5 r[X] per individual. There are 271 parameters in total (i.e 15+6 f[X] + 50*5 r[X]).
The allowable ranges and starting values for the main f[X] are defined using the following syntax:-
f[X] ~ P start_x
Here the ‘P’ is short for ‘positive’. This expression is actually a shortcut for:-
f[X] ~ unif(0.0, +inf) start_x
Where a ~unif() distribution is used to define a range of allowed values [0.0, +inf]. Note, it’s quite common to require PK/PD model parameters be non-negative, in order to make physical sense. The ‘start_x’ value is the initial value for f[X] used in the optimisation, which is usually an initial guess by the modeller.
Each individual has a unique r[KA, CL, V1, Q, V2] vector, because the random effects are defined at the ID level. For more info on the syntax above see EFFECTS. The r[X] are here defined as a zero-mean, multi-variate normal distribution:-
r[KA, CL, V1, Q, V2] ~ mnorm([0,0,0,0,0], f[KA_isv,CL_isv,V1_isv,Q_isv,V2_isv])
Note the second parameter of ~mnorm() distribution, the square covariance matrix f[KA_isv, CL_isv, V1_isv, Q_isv, V2_isv] is a population parameter shared by all individuals.
When fitting a model, the f[KA_isv, CL_isv, V1_isv, Q_isv, V2_isv] matrix is defined using a ~spd_matrix() distribution:-
f[KA_isv,CL_isv,V1_isv,Q_isv,V2_isv] ~ spd_matrix() [
[0.05],
[0.01, 0.05],
[0.01, 0.01, 0.05],
[0.01, 0.01, 0.01, 0.05],
[0.01, 0.01, 0.01, 0.01, 0.05],
]
Where spd is short for symmetric positive definite. This distribution will always return a matrix with positive eigenvalues, starting with an initial matrix:-
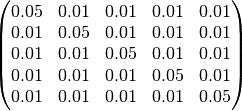
Note as the initial matrix is symmetric it is only necessary to specify the lower triangle elements. PoPy will update the 15 free elements of this matrix to increase the likelihood fit.
Given the f[X] and r[X] the mapping to the m[X] for each individual is defined in the MODEL_PARAMS section:-
MODEL_PARAMS: |
m[KA] = f[KA] * exp(r[KA])
m[CL] = f[CL] * exp(r[CL])
m[V1] = f[V1] * exp(r[V1])
m[Q] = f[Q] * exp(r[Q])
m[V2] = f[V2] * exp(r[V2])
m[ANOISE] = 0.001
m[PNOISE] = f[PNOISE]
This shows that the m[KA], m[CL], m[V1], m[Q], m[V2] parameters for each individual are modelled as log normal distributions with median values of f[KA], f[CL], f[V1], f[Q], f[V2]. There is a shared proportional noise parameter f[PNOISE] for all individuals. And small fixed additive noise constant m[ANOISE]. For more info on the syntax above see MODEL_PARAMS.
A two compartment model with first order elimination and bolus dosing via a depot compartment is defined in the DERIVATIVES section:-
DERIVATIVES: |
# s[DEPOT,CENTRAL,PERI] = @dep_two_cmp_cl{dose:@bolus{amt:c[AMT]}}
d[DEPOT] = @bolus{amt:c[AMT]} - m[KA]*s[DEPOT]
d[CENTRAL] = m[KA]*s[DEPOT] - s[CENTRAL]*m[CL]/m[V1] - s[CENTRAL]*m[Q]/m[V1] + s[PERI]*m[Q]/m[V2]
d[PERI] = s[CENTRAL]*m[Q]/m[V1] - s[PERI]*m[Q]/m[V2]
The bolus arrives in the Depot compartment, due to the @bolus term appearing on the right hand side of the d[DEPOT] equation:-
d[DEPOT] = @bolus{amt:c[AMT]} - m[KA]*s[DEPOT]
The amount of the bolus dose is c[AMT], which is defined in the data file. In this case it is always 100 units and occurs at time point 2.0 for all individuals. The elimination rate from the Depot compartment is m[KA], which is first order with respect to s[DEPOT].
The Central compartment, which represents the blood plasma and where drug concentration observations are made is defined as follows:-
d[CENTRAL] = m[KA]*s[DEPOT] - s[CENTRAL]*m[CL]/m[V1] - s[CENTRAL]*m[Q]/m[V1] + s[PERI]*m[Q]/m[V2]
This consists of the input from the Depot m[KA]*s[DEPOT] and a first order elimination expression s[CENTRAL]*m[CL]/m[V1] that represents the removal of the drug from the blood plasma. Here the elimination rate is expressed as a ratio of:-
m[CL]: clearance from Central compartmentm[V1]: volume of distribution of Central compartment
The last two terms - s[CENTRAL]*m[Q]/m[V1] + s[PERI]*m[Q]/m[V2] are simply the negative values of the rates for the Peripheral compartment:-
d[PERI] = s[CENTRAL]*m[Q]/m[V1] - s[PERI]*m[Q]/m[V2]
To compute the objective function for each row of the data set, the s[X] values are used to compute p[X] prediction variables which are then compared with the target c[X] values from the data file, as defined below:-
PREDICTIONS: |
p[CEN] = s[CENTRAL]/m[V1]
var = m[ANOISE]**2 + m[PNOISE]**2 * p[CEN]**2
c[DV_CENTRAL] ~ norm(p[CEN], var)
The predicted variable p[CEN] is defined as follows:-
p[CEN] = s[CENTRAL]/m[V1]
Hence this is a concentration, because we are dividing the amount s[CENTRAL] by the volume of distribution of the Central compartment. The other two lines:-
var = m[ANOISE]**2 + m[PNOISE]**2 * p[CEN]**2
c[DV_CENTRAL] ~ norm(p[CEN], var)
show that we are comparing the model prediction p[CEN] with the data c[DV_CENTRAL] and using ~norm() distribution likelihood error model. The variance is a proportional noise model, where the standard deviation of the proportional noise is m[PNOISE]. Here m[ANOISE] is fixed to a small positive constant, this is to avoid zero variances when p[CEN] is close to zero. For more info on the syntax above see PREDICTIONS.
PoPy is essentially trying to find the best combination of fixed parameters as follows:-
f[KA]- the median elimination rate from the Depot -> Central compartmentf[CL]- the median clearance of the Central compartmentf[V1]- the median volume of distribution of the Central compartmentf[Q]- the median clearance between the Central <-> Peripheral compartmentsf[V2]- the median volume of distribution of the Peripheral compartmentf[KA_isv, CL_isv, V1_isv, Q_isv, V2_isv]- The covariance structure of thef[X]parameters above over the population of individuals.f[PNOISE]- the proportional noise not explained by the model in thec[DV_CENTRAL]data.
The unexplained noise f[PNOISE] and between subject variance f[KA_isv, CL_isv, V1_isv, Q_isv, V2_isv] obfuscate each other. However the population as a whole contains enough data to solve this problem using maximum likelihood [Sheiner1980].
In PoPy the likelihood is optimised iteratively, with the f[X] and r[X] being updated at each iteration. In this case, the likelihood (or objective function) progressed as follows (Table 24):
| Iteration | Time | OBJV |
| 0.49 | 4694.90605304 | |
| 4.04 | 925.536170281 | |
| 4.25 | 925.536170281 | |
| 1.1 | 7.84 | -659.497864465 |
| 1.2 | 11.15 | -793.657356873 |
| 1.3 | 13.95 | -852.182891771 |
| 1.4 | 16.48 | -878.620958771 |
| 1.5 | 18.76 | -885.472411366 |
| 1.6 | 21.09 | -887.451169134 |
| 1.7 | 23.40 | -888.23668414 |
| 1.8 | 25.72 | -888.67438423 |
| 1.9 | 27.90 | -888.998905873 |
| 1.10 | 30.22 | -889.306967949 |
| 1.11 | 32.42 | -889.646687904 |
| 1.12 | 34.78 | -890.030820355 |
| 1.13 | 37.43 | -890.457037263 |
| 1.14 | 39.75 | -891.662799214 |
| 1.15 | 42.20 | -892.800016912 |
| 1.16 | 44.69 | -893.303452413 |
| 1.17 | 47.28 | -893.667417293 |
| 1.18 | 49.65 | -894.064312222 |
| 1.19 | 52.07 | -894.496052358 |
| 1.20 | 54.46 | -894.948729592 |
| 1.21 | 56.82 | -895.398608733 |
| 1.22 | 59.24 | -895.848882265 |
| 1.23 | 61.67 | -896.292875671 |
| 1.24 | 64.05 | -896.728634677 |
| 1.25 | 66.69 | -897.155601895 |
| 1.26 | 69.12 | -897.575851091 |
| 1.27 | 71.82 | -897.976967314 |
| 1.28 | 74.28 | -898.356653776 |
| 1.29 | 77.00 | -898.705128996 |
| 1.30 | 79.72 | -899.021581241 |
| 82.44 | -899.021581241 | |
| 2.1 | 107.55 | -900.541683179 |
| 2.2 | 121.66 | -901.728157389 |
| 2.3 | 206.82 | -902.720904926 |
| 2.4 | 223.76 | -903.92682679 |
| 2.5 | 237.70 | -904.23126256 |
| 2.6 | 250.62 | -905.053323252 |
| 2.7 | 260.95 | -905.776711809 |
| 2.8 | 273.12 | -906.087586045 |
| 2.9 | 284.88 | -906.977880737 |
| 2.10 | 295.81 | -907.631345268 |
| 2.11 | 306.59 | -908.312470474 |
| 2.12 | 381.17 | -908.883749378 |
| 2.13 | 393.61 | -909.937204118 |
| 2.14 | 407.80 | -911.010605584 |
| 2.15 | 418.07 | -911.215066712 |
| 2.16 | 541.56 | -911.481482898 |
| 2.17 | 572.84 | -912.210755442 |
| 2.18 | 602.15 | -912.434670055 |
| 2.19 | 626.54 | -912.68353212 |
| 2.20 | 645.98 | -912.825004151 |
| 2.21 | 662.86 | -912.932218314 |
| 2.22 | 677.73 | -913.231028165 |
| 2.23 | 752.78 | -913.307671492 |
| 2.24 | 771.55 | -913.457890807 |
| 2.25 | 841.43 | -913.483220033 |
| 2.26 | 925.77 | -913.798314261 |
| 2.27 | 1068.07 | -913.826789364 |
| 2.28 | 1134.54 | -913.866130135 |
| 2.29 | 1199.96 | -913.893845363 |
| 2.30 | 1266.15 | -913.952903963 |
| 1266.15 | -913.952903963 |
Note that the objective function is defined as -2 * the log likelihood. Therefore the lower the objective function the more likely the input data will be observed given the current f[X] values. By default PoPy stops the fitting algorithm once the objective function has stopped decreasing.
Visual Predictive Check for Two Compartment PopPK Model¶
The Fitting a Two Compartment PopPK Model section showed fitting a PK/PD model to a data set.
As shown previous in Visual Predictive Check for Simple PopPK Model. It is possible to use the fitted fixed effects values, i.e the optimised f[X] variables, to generate a visual predictive check, often abbreviated to ‘VPC’.
Running the MSim Script¶
It is presumed that you have already run the ‘builtin_fit_example.pyml’ script from Fitting a Two Compartment PopPK Model. If you have then you should have access to the following output folder:-
builtin_fit_example.pyml_output/
msim/
builtin_fit_example_msim.pyml
You need to Open a PoPy Command Prompt in the ‘msim’ sub folder then do:-
$ popy_edit builtin_fit_example_msim.pyml
To open the MSim Script in an editor. You can then run the script using:-
$ popy_run builtin_fit_example_msim.pyml
If you run this script the following .svg file is output:-
builtin_fit_example_msim.pyml_output/
DV_CENTRAL_sim,DV_CENTRAL_wrt_TIME_SINCE_LAST_DOSE_comb_quant_sim_vpc/
000000.svg
This graphic should look something like Fig. 41:-

Fig. 41 Visual Predictive Check for Complex PopPK model.
Here the y axis is the concentration in the Central compartment and the x axis is the time since the last dose (TSLD). See Visual Predictive Check for Simple PopPK Model for a more general description of the VPC plot shown in Fig. 41.
In this case, the TSLD values are grouped into 12 equally spaced bins along the x axis. Note you need a minimum number of data points in each bin and there are only 250 data points in this toy example. Hence the small number of bins.
The blue dots (original data) are mainly shown to give some visual corroboration of the quantiles (solid blue line). In this graph there are only 12 bins and therefore each bin is quite wide, therefore some data points are grouped together inappropriately. This grouping issue is most obvious at the smaller values of TSLD, during the drug uptake period, when the drug is being mainly absorbed into Central compartment and has not been cleared from the blood plasma yet (see Fig. 41). Only more data and more bins can really fix the issue.
Syntax in the MSim Script¶
For each individual in the original data set, new synthetic data sets are created by sampling new random effects r[X] variables and new measurement noise for all data rows. i.e. The synthetic populations vary due to sampling the r[X] for each individual here:-
EFFECTS:
ID: |
r[KA, CL, V1, Q, V2] ~ mnorm([0,0,0,0,0], f[KA_isv,CL_isv,V1_isv,Q_isv,V2_isv])
And adding measurement noise here:-
PREDICTIONS: |
p[CEN_sim] = s[CENTRAL]/m[V1]
var = m[ANOISE]**2 + m[PNOISE]**2 * p[CEN_sim]**2
c[DV_CENTRAL_sim] ~ norm(p[CEN_sim], var)
This procedure creates a set of N new data sets, which can be compared with the original data set. Where N is defined here:-
OUTPUT_OPTIONS:
n_pop_samples: 100
You can increase the number of samples, to make the VPC more representative of your model. The more complex the PK/PD model, the more synthetic data samples you will need.
As this model has more parameters compared to the Fitting a Simple PopPK Model using PoPy, it may be worth increasing the ‘n_pop_samples’ and re-running the MSim Script. This is left as an exercise for the reader.